
Policy Gradient 初探
简介
Policy Gradient 是 RL 算法中一个基础的模型。我们将结合游戏例子进行说明,以Pong游戏为例,Pong游戏界面中有左右两个白条,分别代表游戏双方,他们打网球一样,当一方就不到球时,另一方得分,先获得21分的一方获胜。

我们在玩pong游戏的时候会根据球飞来的位置控制自己的球拍作出向上或者向下的操作。正确的操作会使得我们接到球,然后打回去,对方接不到的话就赢了游戏。相反,错误的动作会使得我们接不到球,输掉游戏。在这里我们为了易于表示做出以下定义:
- 球飞来的位置,以及自己球拍的位置等当前游戏环境定义为:state, 用s表示。
- 根据state进行的操作定义为:action, 用a表示。
- 将每次action得到的结果定义为:reward,用r表示。
Let's Play The Game
现在开始玩游戏了! 假设我们玩了4个回合,每一回合的具体操作如下:
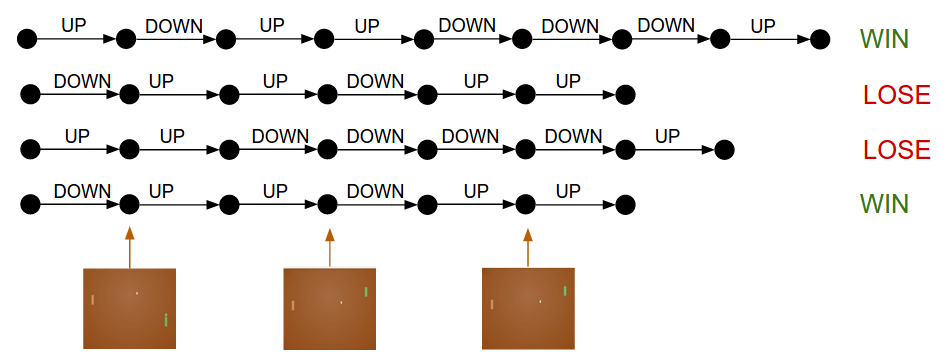
我们将游戏中一个回合的过程定义为:trajectory, 用 表示。
- 该回合游戏结果 为每一次操作的 reward 加权和(如果简单相加可以将看做1):
- 将模型根据当前state生成action的函数,也就是我们的 policy 定义为:
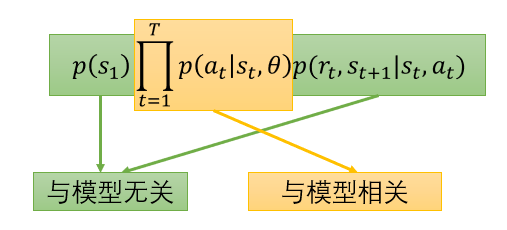
当我们设计一个模型来让他自己玩游戏时,我们将模型的参数定义为 , 而每个回合过程的概率为:
根据上式,我们可以清楚,黄色部分是由模型参数控制的,而绿色部分与模型参数无关。所以黄色部分就可以作为需要去学习的模型,也就我们的 policy ()。
那么当前模型,整局游戏(包含所有可能回合)中的游戏结果 为:
- 由于不能枚举所有的情况,所以随机sample出N个回合,对 进行估计。
How Can We Play Better?
那,我们如何玩的更好呢?
最直接的做法就是最大化 的值, 用常见的SGD来求的话,公式表达如下:
接下来就是计算梯度 :
其物理意义是,
- 当 时, 为使 加大,调整 加大 ,从而达到效果。
- 当 时, 为使 加大,调整 减小 ,从而达到效果。
引用一张Andrej Karpathy blog博客的图来加以说明:
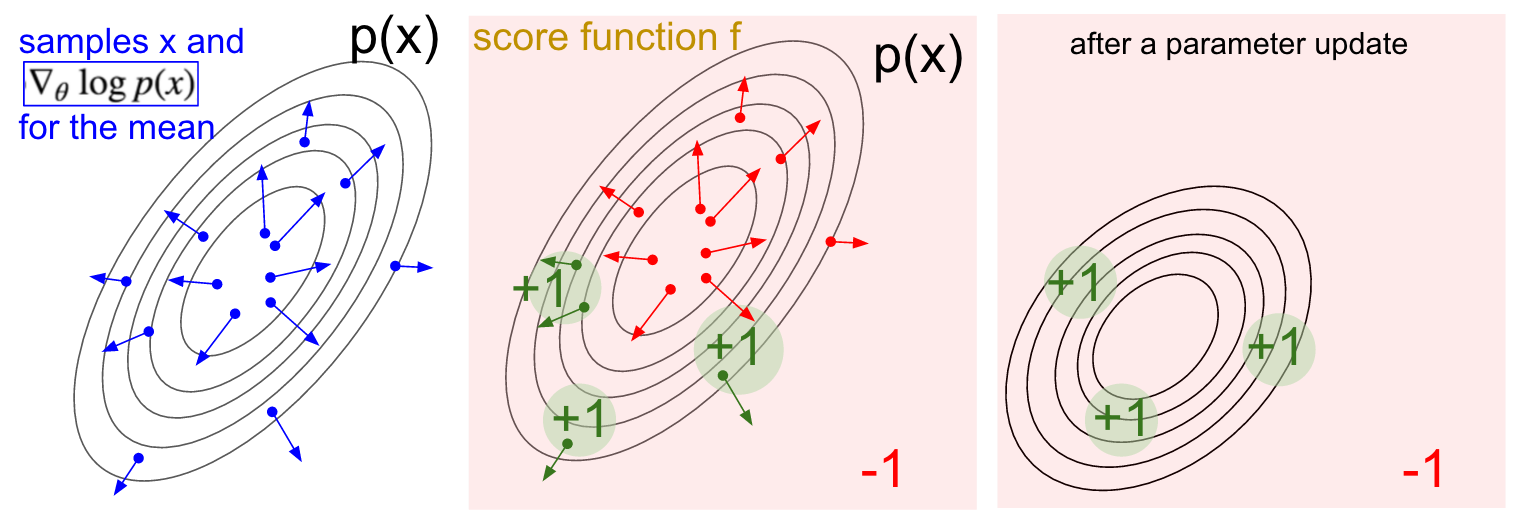
- 左图,高斯分布的选取点求梯度的图,箭头指向的方向都是函数上升的方向。
- 中图,加入reward之后,会提示选取点哪些方向是不好的,比如红色方向可能会导致函数值下降,所以需要走反方向,而绿色点的方向是函数值上升的方向。
- 右图,经过参数更新后,所有点都向绿色的区域靠近,因为那里可以使函数值上升。
知道了学习的过程,我们将玩游戏过程结合在一起就是下图:

Code
根据原理,我们就可以尝试去写一个基于Pytorch的Policy Gradient模型去玩Pong游戏了。可以在gym上找到对应环境。
参考
Deep Reinforcement Learning: Pong from Pixels
Applied Deep Learning /Machine Learning and Having It Deep and Structured